Huffman Encoder in C
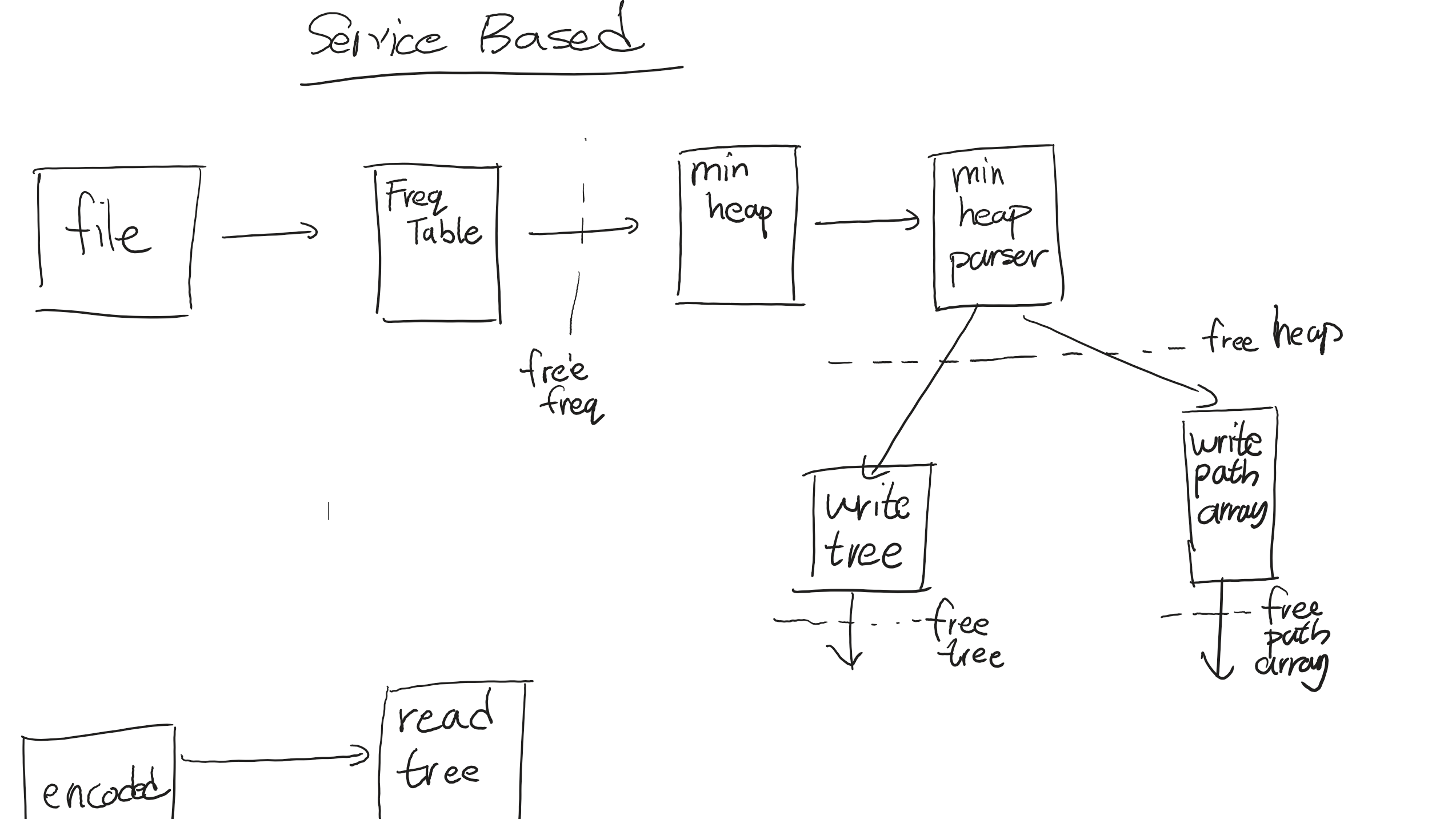
The final course project for my second year computer science course was to create a Huffman encoder in C that would work for a file consisting of purely ASCII values. Having so much fun completing the project, and looking to procrastinate on studying for finals, I decided to create another version that would work for any file by accepting all binary data (not just ASCII values). This ended up introducing much more complexity than I originally anticipated. I learned a lot about low-level programming, data structures, and debugging in C, skills and lessons I’m happy to share with you all today.
Hurdle 1: Writing Bits in Bytes
The first issue was—unbeknownst to younger me—the easiest problem I’d be coming across. The OS does not allow addressing segments smaller than char. The solution to this is to create an 8 bit long queue. I called this the BYTEQUEUE and is used by the fileio_encode.c and fileio_decode.c files.
An additional problem is figuring out the end of the file. As a series of 0s would still be considered valid data in Huffman encoding, I’d need to way to represent the last few bits. A few possibilities were derived such as adding the length of the file or number of bits. These methods, however, would require some form of delimitator separating from real data and would grow as the file grows, both of which I was trying to avoid.
Instead, I decided to write an additional 1 followed by however many 0s it took to conclude the last byte. This way, before reading the new file, I would read the last bit, count the number of 0s there were before the 1, and store that as an end_of_file_offset. Then, in the function to read the next byte, we would check if this is the last byte. If this is the case, we would turn on an end_of_file_flag and pass in a 1 as the MSB when reading the last bit.
Here’s a piece of the code below:
void update_end_of_file_offset(DECODE_FILE_IO *file_io) {
// get the last byte
fseek(file_io->file, -1, SEEK_END);
uint8_t last_byte;
fread(&last_byte, 1, 1, file_io->file);
// count number of bits until the first 1
for (int i = 0; i < BYTEQUEUE_SIZE; i++) {
if ((last_byte >> i) & 1) {
file_io->end_of_file_offset = i + 1;
break;
}
}
// reset the file pointer
fseek(file_io->file, 0, SEEK_SET);
}Hurdle 2: The Mysterious Bit shift
Everything was working! Except.. sometimes my “j”s would turn into “k”s or other letters would find a way to be shifted by one character… I ask that the reader takes a step back and tries to think about what the problem is here. Perhaps it is obvious and it is I that was the fool.
The problem? I was reading the character using the fgetc function, which returns an int. But I was storing it in a char as I was only concerned with the 8-bits that I would later separate using bitwise logic. However, there is good reason why the function returns an int. EOF does not have an 8-bit representation! It is often represented as -1, which I would be able to differentiate if I decided not to truncate to 8-bits.
But I didn’t reach the end of file, in fact I never actually read the data from the end of file as I check for it before I ever actually read one. So what’s going on here? Apparently—and I’m not entirely clear on this concept yet—but when fgetc reads a value, and sees that it is equal to EOF and ends of returning something different than one is explicitly written in the file. Yes, that was a confusing description but I am a confused man right now.
So the solution? Just store it in an int instead of a char, that actually solved all my problems. I lost many hours of my life to this. Here’s what I mean:
// read the next byte
int c = fgetc(file_io->file);
// this should never be EOF as we have checked for end of file
assert(c != EOF);
// as byte is not EOF, cast to uint8_t
uint8_t byte = (uint8_t)c;Hurdle 3: Reducing Encoding Time Complexity
One problem with Huffman encoding is the actual encoding once the tree is created. As I only have access to the root of the tree, finding the encoded value of a particular char in a leaf node would require a full DFS tree traversal. This is unacceptable—in fact I didn’t even code it. Instead, the better method is to go through the whole tree and create a “translation dictionary” that allows us to immediately find the bitwise representation of any given character.
However, my intuition tells me that there should be a better way. I already when through so much work to build the tree from the ground up, why do I have to traverse it again to find the representations.
I had a realization. When we merge two leaf nodes as the Huffman encoding algorithm asks, we immediately know what the last bit of each of those nodes are (0 for left and 1 for right). So I can store these in my “translation dictionary” (called PATHARRAY in the codebase). When merging non-leaf nodes, I can add the second- or third- etc. last bis to all leaf nodes in the left and right subtrees. The result, I now create the translation for each character as I build up the tree.
Code snippet:
while (heap->size > 1) {
// poll the two smallest nodes
HUFFMAN_TREE_NODE *left = poll_min_heap(heap);
HUFFMAN_TREE_NODE *right = poll_min_heap(heap);
assert(left != NULL && right != NULL);
update_paths(left, patharray, 0);
update_paths(right, patharray, 1);Hurdle 4: Storing the Tree
Now I need to find a way to store a tree in as little space as possible. Some strategies I found online involved storing the frequency array but that seemed redundant (I don’t need the frequencies, just the shape of the tree and value of leaf nodes). So instead, I found another strategy on Stack overflow.
We perform an in-order traversal of the tree. Every time there’s a non-leaf node, we write a 0 bit. When there is a leaf node, we write a 1 followed by the character value.
This can then be decoded using a recursive algorithm. Every time a 0 is read, we seek the left and right nodes, and every time a 1 is read, we add the leaf node and return.
Note that this strategy removes the redundance frequency values but only works for complete trees (which Huffman trees are).
HUFFMAN_TREE_NODE *decode_huffman_tree(DECODE_FILE_IO *file_io) {
// read the next bit
uint8_t bit = read_next_bit(file_io);
// if the bit is 1, the root is a leaf node
if (bit) {
// read the character
uint8_t c = read_next_byte(file_io);
// create a leaf node
HUFFMAN_TREE_NODE *root = create_huffman_tree_node_no_freq(c);
return root;
}
// if the bit is 0, the root is not a leaf node
// create a new node
HUFFMAN_TREE_NODE *root = create_huffman_tree_node_no_freq(0);
// recursively create left and right subtrees
root->left = decode_huffman_tree(file_io);
root->right = decode_huffman_tree(file_io);
return root;
}Useful Strategies
Something I only realized while I was celebrating my success in this project, I never didn’t know why my program crashed—a pain I’m too familar with as a C programmer. Something I started doing after watching a YouTube short by ThePrimeagen is “negative space programming”.
Whenever I reach a point in my code and make an assumption such as “the array should be empty when this is called” or “the pointer shouldn’t be at the end,” I add an assertion to make this true. This way, instead of a segmentation fault or core dump, I receive an assertion error that tells me exactly what assumption I made that was wrong.
Here’s an example of what I mean:
void read_and_update_next_byte(DECODE_FILE_IO *file_io) {
// expect the queue to be empty
assert(file_io->bytequeue->current_index == BYTEQUEUE_SIZE);
// read the next byte
int c = fgetc(file_io->file);
// this should never be EOF as we have checked for end of file
assert(c != EOF);
// as byte is not EOF, cast to uint8_t
uint8_t byte = (uint8_t)c;
if (ferror(file_io->file)) {
perror("Error reading file");
exit(1);
}Will definitely be doing this more from now on.
Maybe C isn’t too Bad
I learned a ton about the low level implementations of data structures. Things that I would not have been exposed to had I decided to learn and implement this project in C++. These include creating an array based max-heap consisting of pointers to Huffman tree nodes where the comparisons happen by dereferencing the val field of the nodes.
This love would later inspire me to now do all LeetCode and coding interviews in C++ and assist me a lot in my embedded systems courses.
The Realization
I encoding a 4 gigabyte movie. It worked! But the resulting file was actually bigger than the original… isn’t this called Huffman encoding?
So Huffman encoding is a lossless compression algorithm that works by representing characters in less than 8 bits. The idea is that if you’re not using all 8 bits perfectly evenly, you might as well map the more frequent bits to (for example) 5 bits and map the less frequent ones to 10 bits.
But when looking at large binary files, the bytes are most likely somewhat evenly distributed. So I end up just remapping each character to another set of 8-bits at random and take up more space to store the tree.
Conclusion
I don’t care, this is so fun! I’m actually so happy. Just like when you spend 3 hours cooking a meal and finally get to eat, this has been (days) hours of (sleepless) less rested nights in the works. I called every friend that was up at that hour, let them play with the program, and then sat there encoding and decoding movies, zip files, anything I could think of. This perhaps may have been barely worth losing 3 days of final exam studying for. we both know I wouldn’t have studied either way…